

There are many ways to add search functionality to a Rails application. While many Rails developers choose to use the native search functionality built into popular databases like MySQL and Postgres, others need more flexible or feature rich search functionality. ElasticSearch is probably the most well known option available but it has its own issues. Firstly, it is a resource hungry beast. To run ElasticSearch properly in production, you need a few beefy servers. Secondly, getting ElasticSearch to return relevant search results is not easy. There are many options to configure and knobs to turn. This adds a lot of flexibility, but takes away from simplicity.
Hosted alternatives like AWS Opensearch (formerly known as AWS Elasticsearch) or Algolia can take away a lot of painful hosting problems, but can become expensive very quickly.
For many use cases, there are other, simpler and cheaper alternatives. Typesense and Meilisearch are two that we tried for one of our internal projects at Cloud 66.
After some searching, trials and prototyping, we settled on MeiliSearch so I wanted to share the way we implemented search and integrated with MeiliSearch.
Native MeiliSearch Rails Integration
There is an official MeiliSearch gem with decent documentation you can use to simply index and search your ActiveRecord objects without much hassle. The way the native MeiliSearch / Rails integration works is by annotating your ActiveRecord objects with include MeiliSearch and adding a meilisearch block to your classes:
Now you can search Student
While this is simple, elegant and very effective, our use case was slightly different so we needed to decouple our indexing and search from our basic domain objects.
Using MeiliSearch with an Admin App
 A partial screenshot of MissionControl homepage
A partial screenshot of MissionControl homepage
Internally, we wrote a tool called MissionControl, which helps our teams from sales to marketing to our customer advocates and engineers, support our business. Both of these apps are written in Rails and share the same database. However, the admin app (MissionControl) has readonly access to the database, while the main app handles around 2,000 database operations per second. On top of that, we didn't want to make changes and deploy the main app, every time we need to add a new field to our search index. All of these factors, as well as other security and availability requirements, meant that MissionControl had to take care of its own search functionality and not rely on the main application to keep the search indices up to date, which in turn, meant we couldn't use the native ActiveRecord-based update with MeiliSearch.
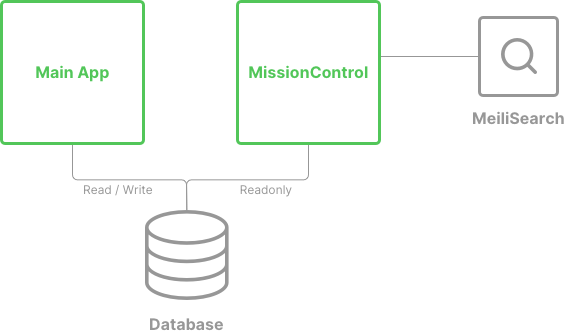 Cloud 66 main app and MissionControl
Cloud 66 main app and MissionControl
Our final design for adding MeiliSearch to MissionControl is as follows:
- A rake task in MissionControl finds all changed records and updates the index
- A second rake task in MissionControl finds all deleted records and removes them from the index.
- Both tasks are scheduled with CRONJobs to run regularly and frequently.
- We can remove the entire search index if needed and the next run will rebuild it from scratch.
Let's get deeper:
First, we need to instantiate a MeiliSearch client. This can be done in a Rails initializer:
Indexing new and changed objects
Now on to the rake tasks. First the index task, responsible for finding updated database records and adding / updating their index:
Let's break down this task further. MissionControl uses ActiveRecord to access the shared database, so classes like ::User and ::Account are vanilla Rails ActiveRecord classes. On each one of these classes, there are some basic database column-based attributes, like email or name that you can see added to classes_to_index. We also have some "dynamic" attributes we wanted to index. This might be from a relationship of the main object. For example, you might want to index the name of the company a user works for alongside the user, however that piece of information might be stored on the ::Account, which has a one to many relationship with the ::User.
To allow this, we used a mix of symbols for basic attributes, and Lambdas for the dynamic ones:
Next we need to read all the unindexed objects from the database. To do this, we use a simple class called IndexMetadata. IndexMetadata is stored in the database and consists of the name of the object's class and the timestamp of the last successful index run for that class. Using this, we can ensure that we only read objects that have an updated_at attribute past the last index timestamp.
IndexMetadata migration
models/index_metadata.rb
Now, back to the task code:
Now we have an ActiveRecord query which we can run to fetch all the objects we need to index for that class. To speed things up, we use a find_in_batches method to read DB records in batches.
Once we have each group, we can iterate through the objects and construct a hash of the object's db columns as well as the dynamic attributes.
As you can see we are also filtering out some of the records that we don't want to index. Once this is done, to_index holds an array of hashes that we can simply push to MeiliSearch where it will be indexed. add_documents adds or updates the documents with the same ID so we don't need to worry about new and existing documents running different code.
Now all that's left is to update our IndexMetadata for the class we just indexed so next time we start from where we left off.
Removing deleted object
The next rake task takes care of removing documents from the index where the object has been deleted from the database. This is very easy if you have some sort of soft delete in your application. But without soft deletion, you simply don't have the record in the database anymore and so don't know what to delete in the index. We solved this by comparing the index with the database:
This tasks has 4 main steps:
- Fetch the IDs of all documents in the index (this is very quick in MeiliSearch)
- Fetch the IDs of all documents in the database (this can be improved using
VALUESif you use MySQL 8.0.19+) but still very fast and memory efficient. - Compare the ID sets and find the missing ones
- Delete the missing ones from the index
Scheduling
You can now schedule these tasks to run every minute to keep your index up to date. While this will not give you a real-time index, it works for many use cases where you want the search functionality to be separate from your main application.
Searching
Searching the index is the same regardless of your indexing method. There is MeiliSearch documentation for both server and client side search methods depending on your requirements and the client's JS stack.