
{<2>} 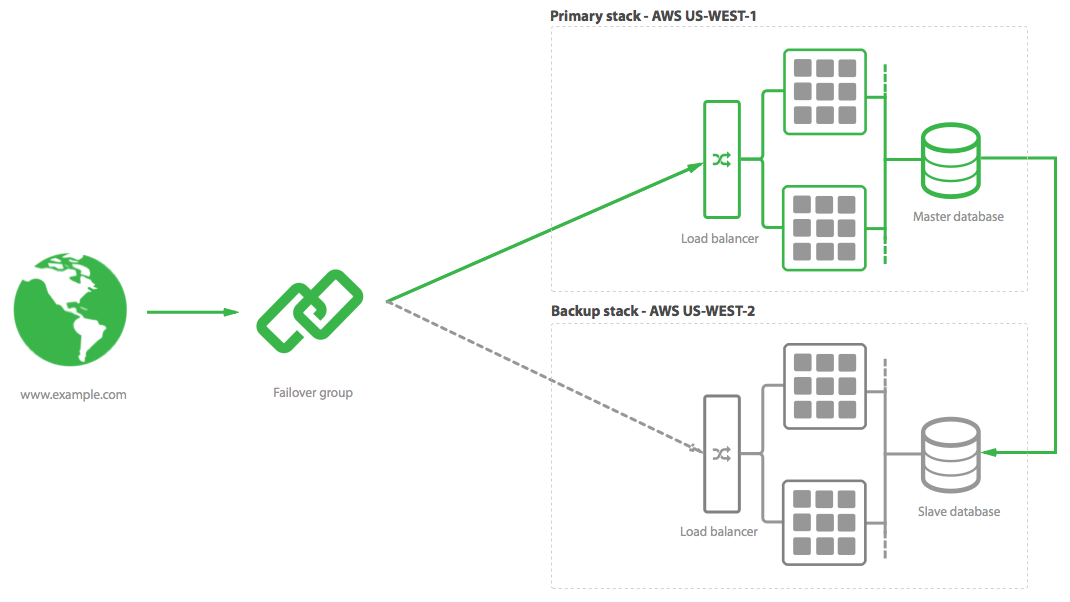
The use of container technology such as Docker has lots of benefits and we're really excited about the possibilities this technology provides. However, running Docker in production comes with a number of difficulties, and doing so with high availability becomes all the more challenging. This post will outline the steps required to achieve high availability Docker stacks, along with how Cloud 66 solves these problems.
Let's start with an example: you have a beautiful Docker stack setup in your cloud provider and region of choice. Everything is ticking away nicely, until one day there's an issue - the hardware on your server breaks down, along with your mission-critical applications. What do you do?
In an ideal world, you're adhering to immutable infrastructure workflows and will be able to setup an identical stack elsewhere. As we all know though, this is easier said than done. Once you have the new stack up and running, you have to migrate your data from an old backup (considering that your database is unavailable) and then switch over traffic to the new stack. All in all, you may be down for many hours.
Now let's see how we can address each of these issues:
Setting up an identical stack
To achieve high availability, your best bet is to have a backup stack already running in a different data center, which is ready to start receiving traffic if and when the main one goes down. You just need to ensure that any code updates that go to your main stack are also reflected on the backup stack, and disable this stack from accepting incoming traffic until it's actually needed.
At Cloud 66, we strive to make it easy to adhere to immutable infrastructure principles. To setup a backup stack, you can simply clone your existing stack to a different cloud data center at the click of a few buttons. This will build an entirely new, identical stack, which you can use in the case of disaster. By using redeployment hooks, you can ensure that both your main and backup stacks are deployed when your code changes.
Migrating your data
In terms of your data, our goal is to prepare for a disaster before it happens. The best way to do this is to setup a master-slave relationship between your main database and backup database. This will effectively ensure that any changes on the master database will be available on the slave. If your master database goes down, you'd promote the slave to be a master, ensuring a quick transition in the event of failure.
You can setup master-slave replication between your MySQL, PostgreSQL, MongoDB and Redis databases through the UI on Cloud 66. Though the process varies for each database, this is a high-level overview of what happens:
- We take a full backup of your main database server and restore it on the backup database
- We setup the master-slave relationship between the databases
- The relevant environment variables are updated for use in your code and scripts
Switching your traffic
On this step, our goal is to ensure that you can swiftly switch your traffic from one stack to another with as few steps as possible. One solution is set the time-to-live (TTL) on your DNS records as low as possible to ensure that any changes are propagated quickly.
The solution we prefer at Cloud 66 is to use a failover group, which creates a DNS record for you to point your domain at. This DNS record has a 300 second TTL, and is controlled through the Cloud UI. When you create this failover group, you attach a primary and backup stack to it, which allows you to switch traffic between your stacks without making any manual DNS changes. This ensures that you have one central location to manage your traffic between stacks.
Conclusion
Setting up high availability Docker stacks in production can be a large overhead, especially considering the many moving parts required to get your main stack up and running. The goal is to ensure that your code, data and traffic can be swiftly moved from one problematic hardware set or data center to another.
Our goal at Cloud 66 is to make the process of achieving high availability more straight-forward, and make this a viable technology for small and big companies alike. If you have specific requirements around high availability, feel free to contact us and we can work together to find a solution.