
Overview
Yesterday (April 6th) our dashboard and API had a 1:53 hour downtime. This meant deployments were disrupted and server heartbeats couldn’t reach us. While no customer stack experienced any downtime or disruption, our customers couldn’t deploy during this time and access to servers were stopped.
Here is dashboard and API our uptime for the last 8 months:
| March | 99.96% | | February | 100% | | January | 99.99% | | December | 99.96% | | November | 99.97% | | October | 100% | | September | 100% | | August | 99.93% | | July | 99.93% |
You can see the rest of our uptime stats here.
While we are proud of providing a high availability service to our customers and many of our other services have a higher uptime, we feel we let you down yesterday and we are sorry about that.
Here is my attempt to explain how this happened and hope this could help other fellow developers avoid downtime of their own services.
When adding monitoring causes downtime
Since the early days of Cloud 66, we’ve relied on New Relic for our server monitoring. We use New Relic to monitor our servers and notify us via VictorOps if there is an issue with a server or a process is running too high on memory. This combined with external monitoring from Pingdom enabled us to run a high uptime service to our customers. This however was only from outside and basic metrics of the servers.
On the APM side, we started using ScoutApp to measure our application performance. We liked ScoutApp since their Rails APM is very specific to Rails and works really well. The metrics from their APM allowed us to improve our application’s performance by a decent margin.
We liked ScoutApp’s Rails APM so much that we decided to look into their server monitoring as well. What attracted us to their server monitoring was the fact that they allow automatic installation a wide range of plugins from RabbitMQ to Nginx and Sidekiq with very little effort and they also support statsd out of the box for custom metrics. Since we use all of the above and statsd, we decided on moving our server monitoring to ScoutApp.
Yesterday as part of enabling monitoring on our frontend Nginx servers we had to make a simple change to our frontend Nginx servers. We tested this change in isolation and then took 1 of the frontend production servers off and tested the configuration on that server. All tests passed: server was serving content locally and remotely to another server in the same network, all upstream services were also available. Next we checked the health check endpoints of the server to ensure they return HTTP 200 so our load balancers can add them back. Once all the tests passed we put the server back behind load balancer. The server was registered by our AWS ELB load balancer and was shown as healthy and In Service.
So far, so good. The new configuration passed all the tests in isolation and in production and the server was serving traffic as evident by the logs and nginx metrics in our newly deployed ScoutApp Nginx metrics dashboard.
It was time to put the new configuration into our git repository and apply it to the rest of the frontend servers. So we did. We put the Nginx configuration in our git repository and applied it to all other front end servers and reloaded nginx. Nginx reloaded fine with no errors and servers showed up in our metrics dashboard as serving traffic. Logs were coming through showing activity as normal and AWS ELB was showing servers as In Service and healthy.
This is when things started to go round. In less than 10 minutes, no traffic was hitting our servers except from a small subset of clients. Our public endpoint started returning HTTP 502 Bad Gateway which was coming out of AWS ELB while the Nginx logs were showing some clients still coming through. During all this time, AWS ELB was showing servers as healthy and In Service, our health endpoint was returning HTTP 200 and internally we could see the service if we were not going through the load balancers.
Steps we took to identify and fix the issue included removal of the servers from the load balancer and adding them again (sometimes ELB takes a while to really register the servers while it’s showing them as In Service). Testing the servers individually and directly, review of our iptables and firewalls to ensure a change in ELB internal IP has not caused blocking by fail2ban as well as inspecting the nginx configuration and reversing the changes in nginx.
At the end it turned out that the issue was caused by a feature in OS X that replaces single and double quotes with “smart” single and double quotes. Here is an example:
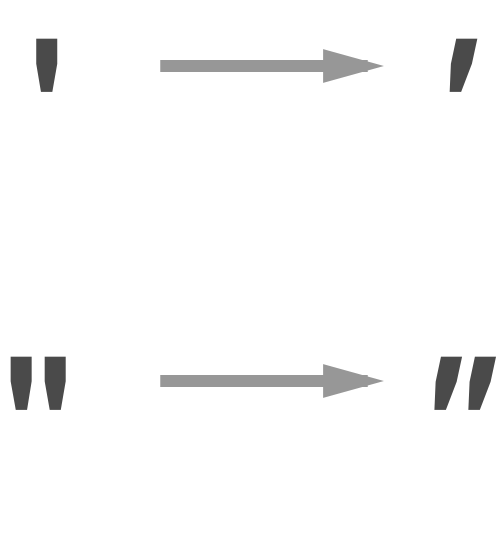
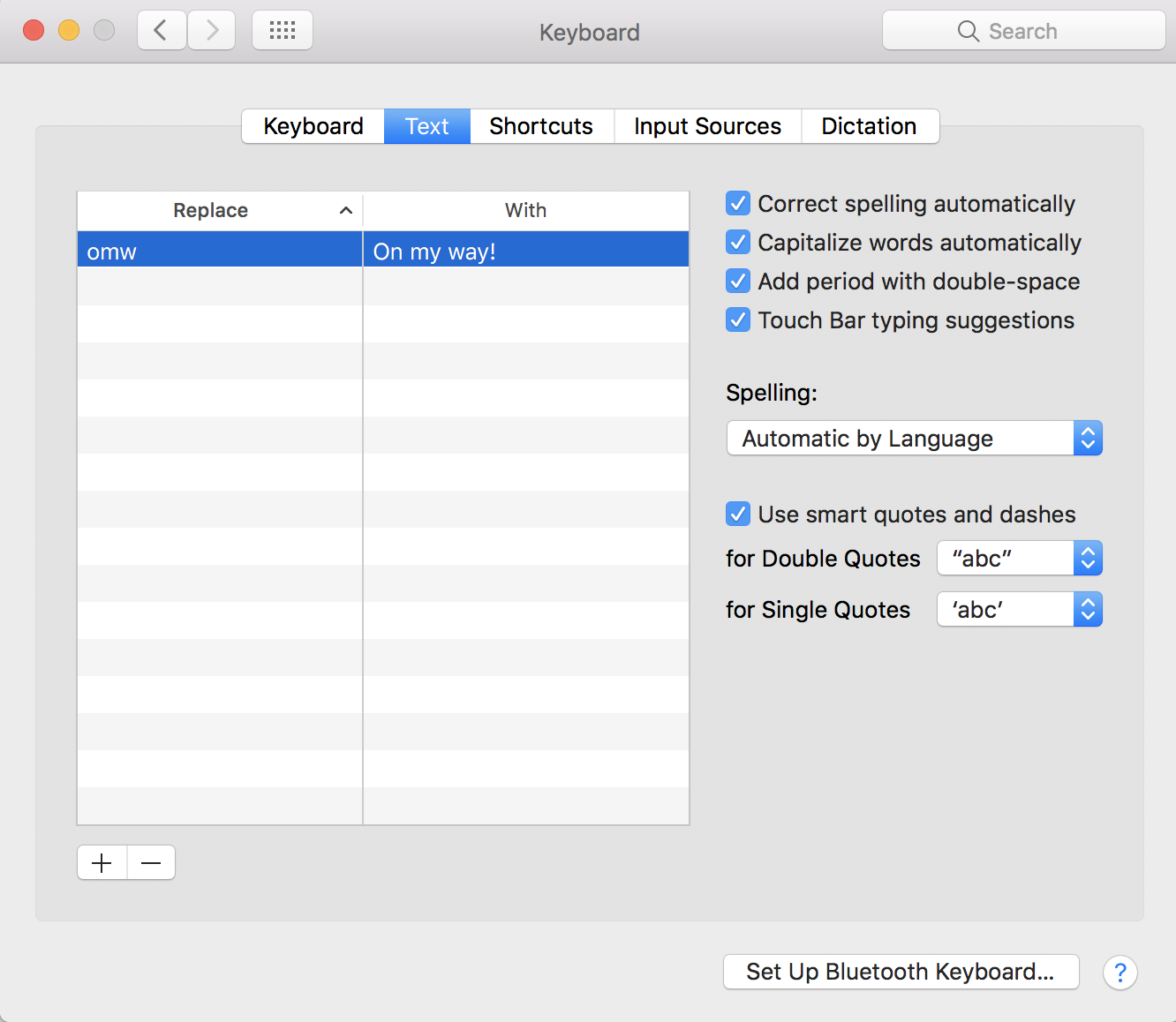
You can find this feature under System Preferences → Keyboard → Text
As it happened the test phase of the new Nginx configuration we copied and pasted it on our OS X machine. This changed the quotation marks for the custom HTTP Headers from a normal quote to a smart quote.
This change doesn’t violate Nginx config validation so Nginx carries on serving the requests. It also is acceptable payload for many clients and browsers. However AWS ELB doesn’t consider those HTTP headers valid and takes the server offline because it has “malformed” payload. The issue is while ELB takes the server offline for this reason, it still shows it as In Service and serves traffic through for some clients (it seems this depends on the client type: all Go net/http clients and Ruby clients were getting through. We are enquiring with the AWS team to clarify ELB internals regarding this).
When this bad character found its way to our git repository it affected all of the servers forcing ELB to take the out of service without warning or any signs and since ELB takes a while (depending on health check failure setup and traffic draining) to stop serving traffic from a server, no change is immediately visible. Combined with the issue in the ELB dashboard that shows servers as In Service, this makes the whole issue difficult to spot.
Since this issue, we have disabled the smart quote feature in our OS X, but that’s not the main point. We’ve also switched our load balancer from ELB to ALB which has a different behaviour in taking servers offline: it actually shows they are offline when something like this happens. We are also going to enforce rules around transfer of files around during development that doesn’t involve copy/paste or Slack file sharing to avoid mistakes like this.
Again, we are sorry for the inconvenience this disruption caused you and thank you for your support and patience.