
Most monitoring systems monitor activity: your CPU utilisation, your disk space, your emails sent count. But many times we need to monitor inactivity, like knowing when a server is not accessible anymore, when a queue worker has stopped picking up new jobs or when an agent hasn’t called home for a while.
Monitoring inactivity is easy at a small scale, but can become tricky at scale. How can you make sure all of your 10,000 agents call back home at least once a minute?
Here I am going to tell you about our approach producing alerts on agents missing a callback home (skipping heartbeats)
Introduction
All servers deployed with Cloud 66 run an open source agent which does two things:
- Detect IP changes of the server
- Send a heartbeat every 1 minute to tell us the server is up and running
IP changes happen on some cloud providers when a hard restart of the server happens. By monitoring IP changes (internal, private, public, IPv4 and IPv6) we can make sure DNS records, firewalls, load balancers and clusters of servers in a stack are always up-to-date.
A missing heartbeat could mean a network issue between the server and Cloud 66 servers, a satirised CPU on the server (no time to send a heartbeat) or a server crash.
We want to know about those issues as soon as possible and take action: alerting the customer, reconfiguring the rest of the cluster if needed and perhaps modifying firewalls.
But how would you detect a skipping heartbeat in 1 of 10,000 servers?
Here is how we did it
Although we want to know about a missing heartbeat as soon as possible, we also don’t want to have a lot of false positives when a heartbeat is missed but the server is ok and is going to send the next one just fine.
Our threshold is 10 minutes for most use cases: 10 missing heartbeats in a row and we are going to raise an alert.
The bulk of the hard work is done by Redis.
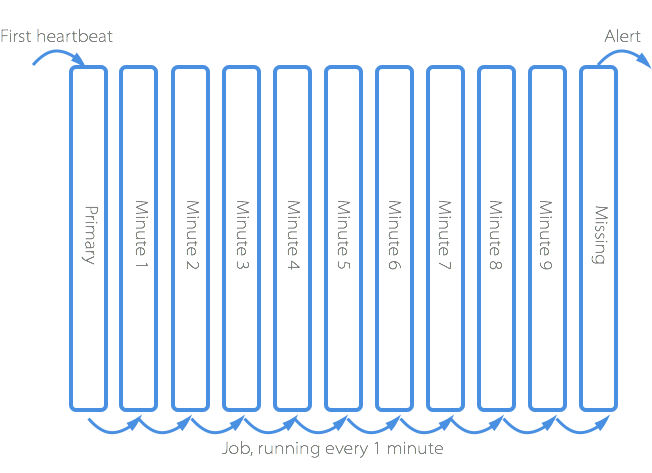
We start by having 11 Redis Sets in Redis:
primary, minute_1, minute_2, minute_3, … minute_9, missing.
The first time a heartbeat is received from a new agent, its agent ID is stored in the primary Set, and all other sets are scanned for the agent ID. If the agent ID is found in any of the sets, it is removed from it.
Every minute, a job runs and moves all agent IDs from the primary to minute_1 and all agent IDs from minute_1 to minute_2 set and all anent IDs from minute_2 to minute_3 and so on. You get the idea. By the end, any agent IDs in minute_9 set will be moved to the missing set.
Once that’s done, any agent IDs in the missing set have been missing 10 heartbeats in a row.
A Redis Set can store up to 4 billion items, so we should be good for a while! Also by using Sorted Sets, the scan time for agent IDs is very fast.
The only issue with this approach is that each agent should send at least one heartbeat to be tracked. This can be fixed by adding each new agent to the primary set automatically.