

Our “8 Components” blog post, which was written quickly over lunch before the holidays, has turned out to be an all-time favourite—we even turned it into an eBook, complete with our own war stories.
One of the areas highlighted in the post and eBook was the container pipeline, and on popular demand, in this post I will aim to expand a bit on why current pipelines don't cut it, what a CDP needs to cover, and how we approach this challenge.
A faster engine, but not enough fuel
The release of AWS’s managed Kubernetes (EKS) and abstraction layer (Fargate) in late November of last year was an important moment for Kubernetes and the CNCF, but not only because it helped further cement the orchestrator’s dominance. It also signalled to container platform vendors that the days of getting excited about Kubernetes-with-a-UI are effectively over.
But things are far from settled. Removing one bottleneck usually exposes a handful of "new" ones around it. To bring back to containers: now that clusters will be moving much faster, what key components will slow us down?
We think an interesting and critical area to look at is the pipeline.
How to think about a pipeline
Broadly, there are three main approaches to a container pipeline today:
- Build a stack of open source projects and automation scripts. Low software costs, high operational cost. Can be difficult to maintain and scale.
- Pay someone to build no. 1 for you, or use a managed service. Can be expensive, but at least minimizes hidden costs of the previous case.
- Use a hosted CI tool. Usually inexpensive, but usually does not "speak config", which is essential in Kubernetes.
OwnStack and Managed OwnStack. Someone I used to work with said once, "in cloud, open source software often means closed-source operations; you're locking yourself in to either your own practices, or to a cloud vendor". I find this is especially relevant for more fragmented and younger ecosystems, such as containers.
Example: a friend of mine works for a major financial institution, and is part of an all-star cloud engineer team. They use a complex set of open source tools and homemade automation scripts. Of one of these tools he said, "that project is small, and the maintainer sometimes goes off the grid and things can stay broken for a while, but we can handle it in-house".
The question is, when it comes to scaling that anecdote up into production, how many companies can afford the talent to do the same? A fully open-source stack could prove prohibitively expensive (in terms of operational costs) to build, automate, scale and maintain—which is why many companies turn to SIs and MSPs for help in building that OwnStack. However, that is usually an expensive exercise, and has the risk of not being sustainable as Kubernetes and the CNCF landscape continues to evolve (and fast!). Users have told us that a managed OwnStack could cost upwards of 5x of a product approach.
Specifically for pipelines, large-scale users have told us that an OwnStack is tough to setup and upgrade, to standardize between teams and regions, to secure (e.g. deal with credentials distribution), and, ultimately, to scale.
Hosted CI. Everyone has their way of doing things, and change can be painful—so the inclination to leverage friendly, existing tools with their familiar, old ways of doing things is very human. However, in some cases, the change is so meaningful that these trusted tools and practices start slowing us down.
Take build & test. I thought that this post broke down the problem very well. When my app is made of numerous unique elements, it becomes very difficult to test for issues before this complex, fragile structure is deployed. By the way, it can be rebuilt and redeployed within minutes, which means testing needs to happen across the lifecycle, and take into account wildly different environments and substrates
The emphasis shifts from the pre-deploy test to the ability to reiterate often and quickly within a well-controlled policy.
Time for a Container Deployment Pipeline
Kubernetes brings Devs and Ops closer together, and to avoid the complexity of the infrastructure impacting development pace, a Container Deployment Pipeline (CDP) solution should facilitate efficient maintenance of container delivery that is consistent with the code.
To recap the CDP section of our eBook, a CDP needs to:
Understand that microservices require a pipeline-wide view, from Git to Kubernetes;
Automate that pipeline while providing advanced observability, security and policy management;
"Speak config" automate creation, control and versioning of production-minded config files for any environment (easy environment creation should mean easy operations!);
Be easily scalable and deployable across teams, clusters and regions.
Here’s a graphic representation of what a CDP should cover (functions also available in common CI tools are marked by a green asterisk):
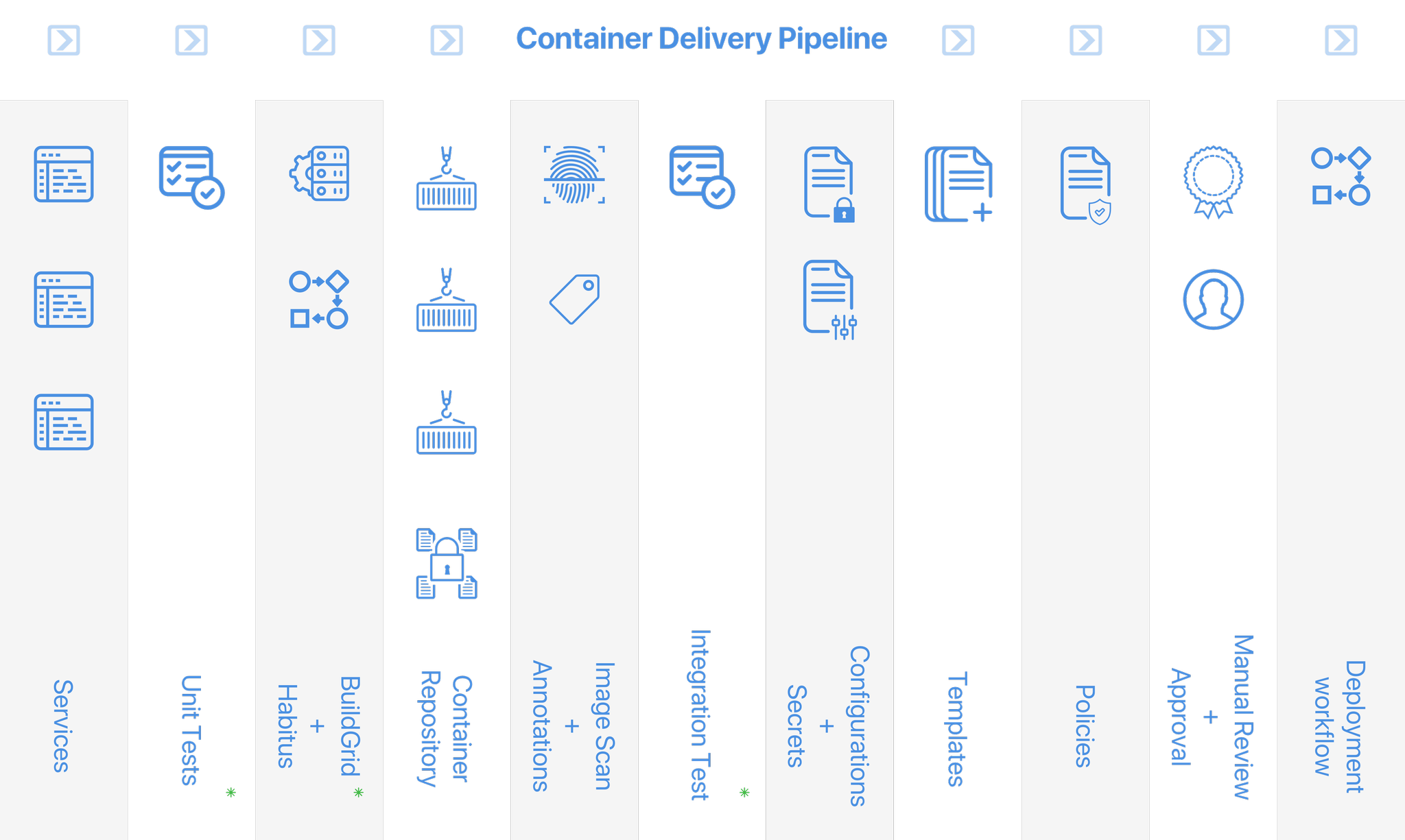
All of that is covered by our pipeline, Cloud 66 Skycap, which has exciting new features on the way for even more automation, governance and flexibility.
Sign up for a free, full-functionality 14-day trial here.
Lastly, come talk to us at KubeCon (promo code included!) or at these conferences: CloudFest // CloudExpo // RailsConf.