

Nowadays with all the computer power at our disposal, it's a great era for machine learning. Complex equations can be calculated faster as ever and everybody can start experimenting with machine learning. Do want to give it a try too? This blog is a very simple primer into the exciting world of machine learning and comes with a working demo written in Node.
What is machine learning.
Machine learning is the art of using computer algorithms to learn from experiences and use those experiences for future predictions.
Tom Mitchell gave a really simple definition of machine learning. Here we go:
A computer program is said to learn from experience (E) with respect to some task (T) and some performance measure (P), if its performance on (T), as measured by (P), improves with experience (E).
This definition dazzled me a bit too, in human language:
So if you want your program to predict, for example, buy patterns at a busy grocery store (task T), you can run it through a machine learning algorithm with data about past buying patterns (experience E) and, if it has successfully learned, it will then do better at predicting future buy patterns (performance measure P). With the buying pattern prediction, you can respond accordingly and give the customer tailor-made discounts for example.
Supervised machine learning
If you look at our definition we need some past buying patterns. This is called a training set. Using machine learning with a training set is called supervised machine learning. The program is trained on a pre-defined set of training examples , which then facilitate its ability to reach an accurate conclusion when given new data.
Under supervised machine learning there are two major subcategories.
Regression machine learning systems
Systems where the value being predicted falls somewhere on a continuous spectrum. These systems help us with questions of 'How much?' or 'How many?'.
Classification machine learning systems
Systems where we seek a yes-or-no prediction, such as 'Is this tumer cancerous?', 'Does this cookie meet our quality standards?', 'If I bought cookies last week, will I buy shampoo?', and so on.
In this blog post will experimenting with classification. We are going to use Naive Bayes classifiers. Naive Bayes classifiers, a family of classifiers that are based on the popular Bayes’ probability theorem, are known for creating simple yet well-performing models, especially in the fields of document classification and disease prediction.
If you want to know more about Naive Bayes classifiers. Here is a great article written by Alexandru Nedelcu.
Let's get started.
A simple machine learning App
I created an example use Node and consists of two services; the API and the trainer.
The API is responsible for feeding 'historical data' to the trainer and ask prediction questions to the classifier with a trained model. We use a MongoDB for document storage and the storage of our trained model, a serialised object.
The trainer is responsible for training the model using the historical data found in the datastore. The trainer worker which will train continuously and will store the trained model to mongo. If somebody requests a prediction through the API it will retrieve the latest trained model. The schema below show all the components.
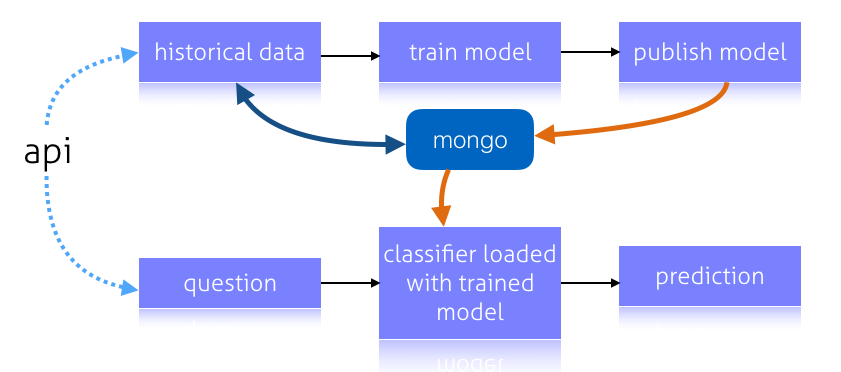
The code for the machine learning application can be found on Github. The code has comments and I think it's so simple it self-explanatory. Check it out and start the machine learning bandwagon today ;-)
Start the App
The code has two subdirectories called API and trainer. Both contain the package.json, a Dockerfile and the main.js. They are using the Node package monk for MongoDB management. Express.js for the API and the awesome natural language machine package called Natural.
Docker
If you are into Docker development, the easy way to start the example is to use docker-compose. Just run docker-compose up. Don't forget to build the images first: docker-compose build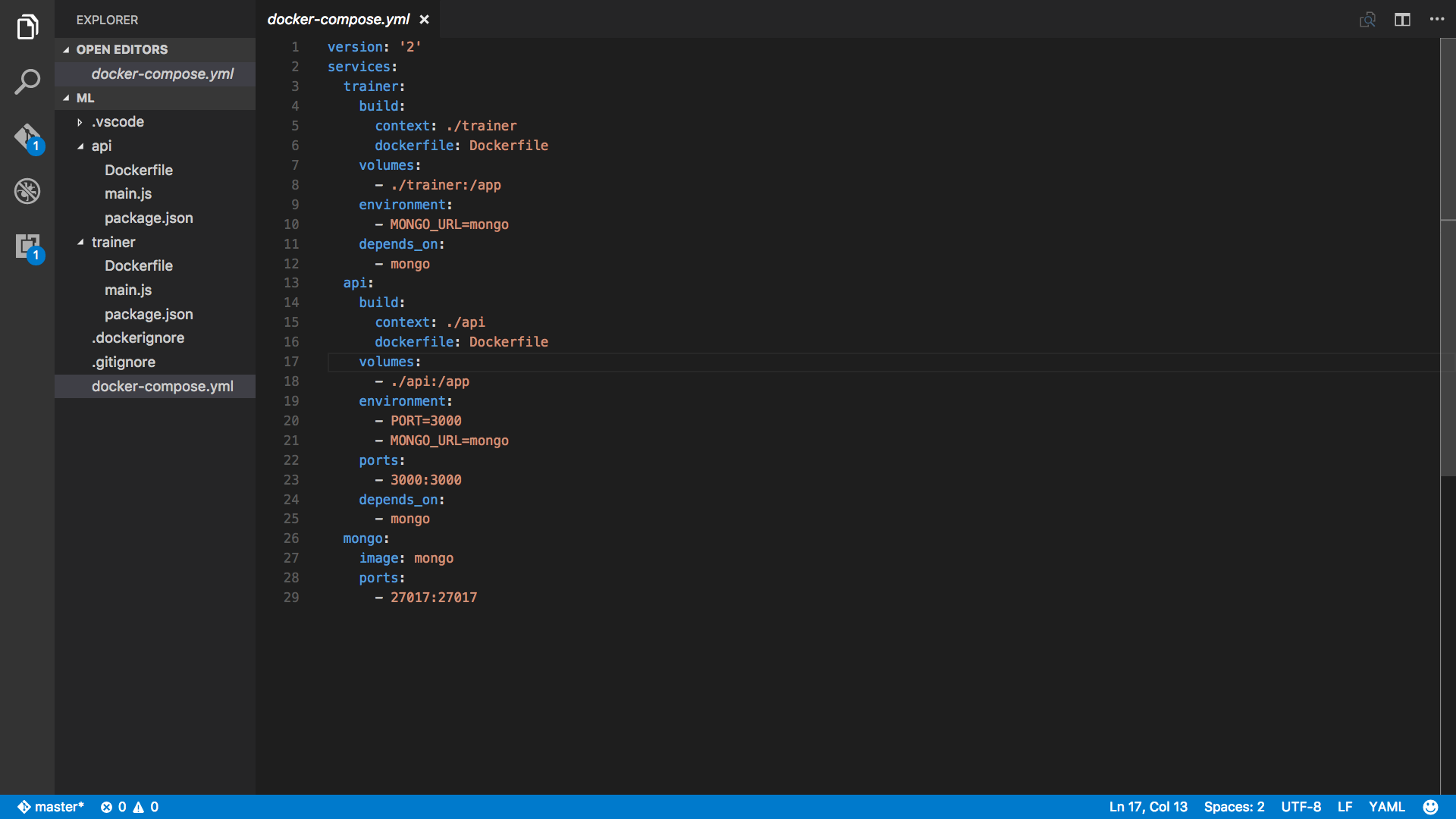
Adding historical data for training
When the app is started, the trainer will start training and you can feed the model using the API endpoint http://127.0.0.1:3000/training to POST some historical data.
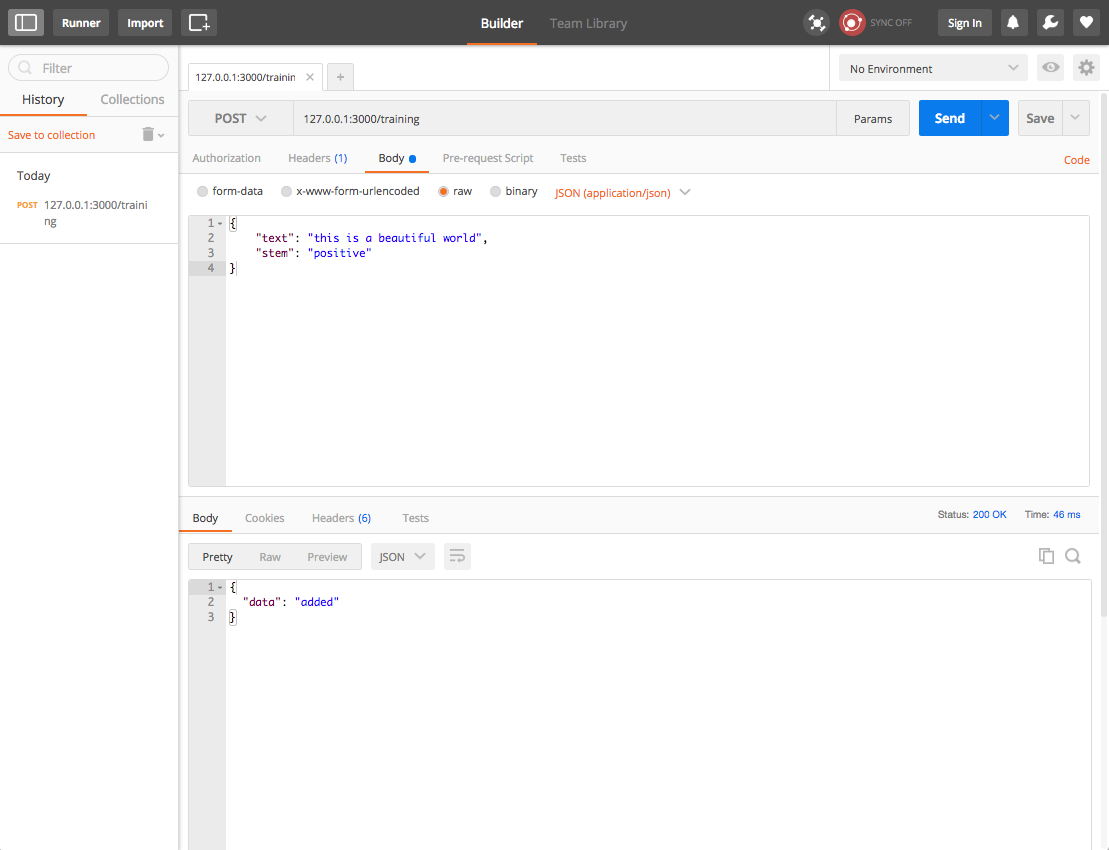
Here an example using Postmen. We are going to post a text 'this is a beautiful world' with is stemmed with the label ' positive'. Play with this API call and add more ' positive' and ' negative' text. When done, the model is trained and you can start prediction if the sentence is ' positive' or ' negative'.
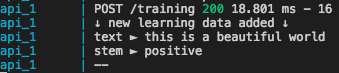
Training the model
The trainer is running a loop using a process manager and will make the model better if there is more historical data.
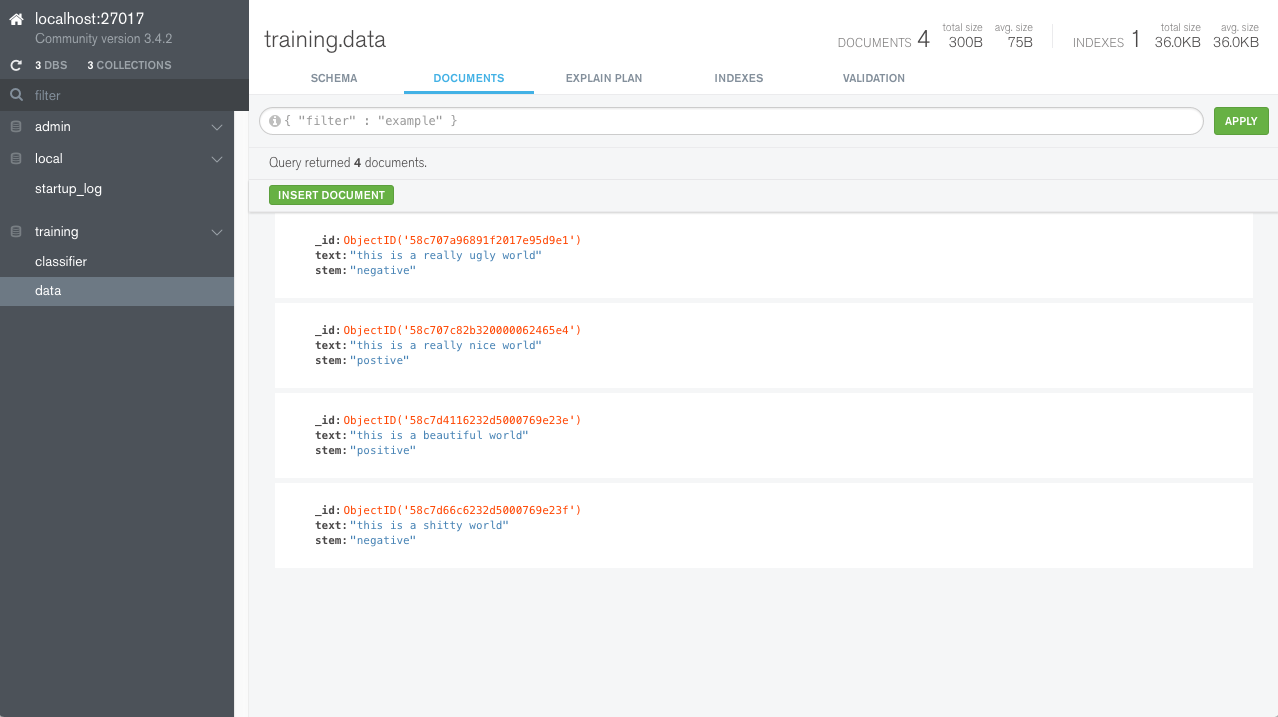
Here is a snapshot of the data in the database:
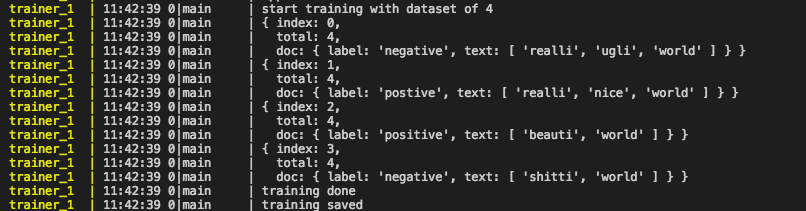
This is the output of the trainer with this very minimal data set:
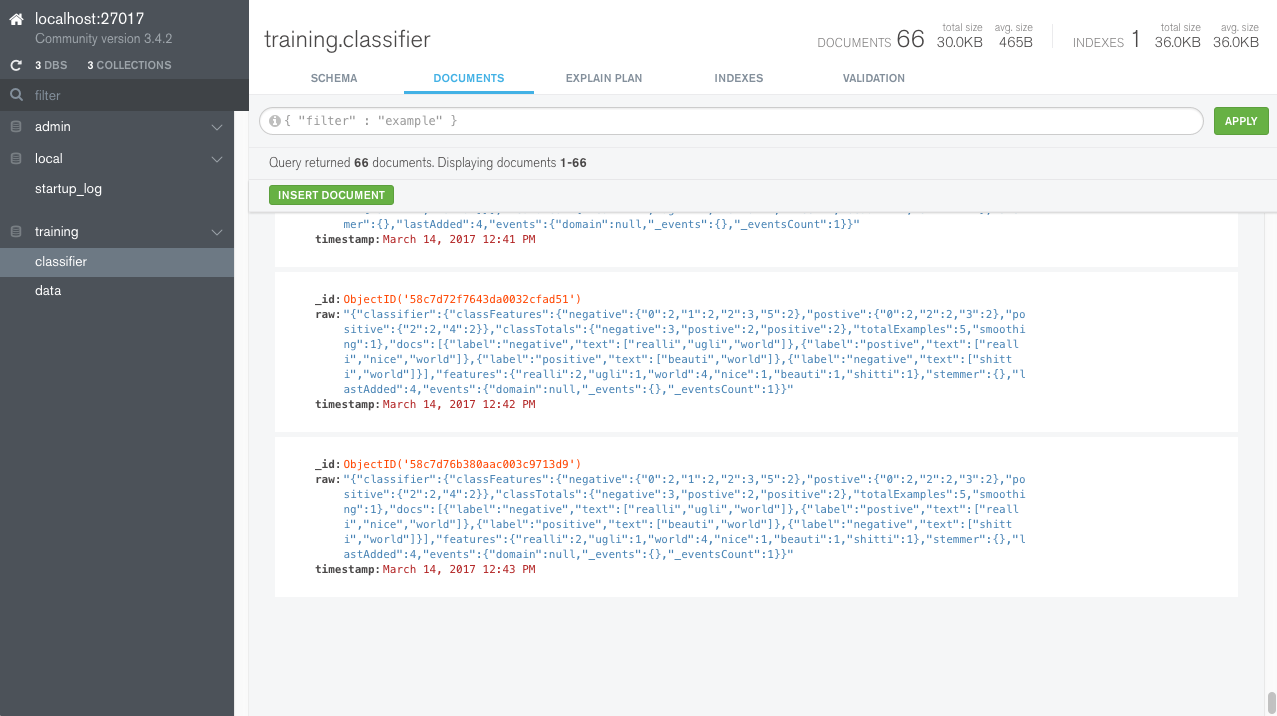
You can see after training it saved the model in MongoDB for later retrieval doing predictions. If you look in the database you find the persistent model:
Doing predictions
Ok. We trained the model, time to do some predictions. Just hit the /predict endpoint with a text and the classifier, with the loaded trained model, will give you an answer if the text is 'negative' or 'positive'.
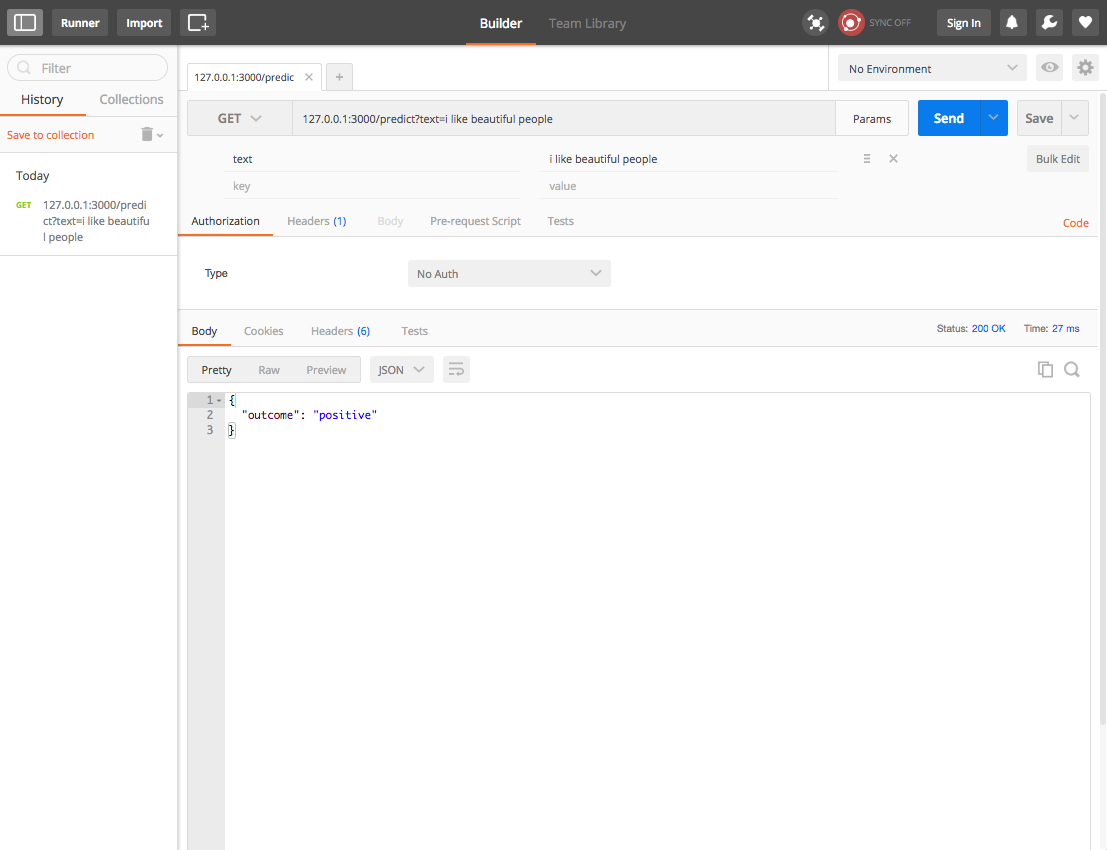
I send a new sentence 'I like beautiful people' to the API which is not in the training set and the classifier knows it belongs to the 'positive' stem. So cool!!!
Deploying in production
Running a machine learning systems on your local system is just the start. If you want to run heavy algorithms in production you need a good deployment system and hardware. With Cloud 66 you can deploy your Node application or any containerized machine learning app to any cloud or bring your own bare metal servers if you like.
Have fun with machine learning, Node and Cloud 66.