

How do you find hard-to-come-by biopharma data to achieve better clinical outcomes? A tech startup specializing in data intelligence, Amplion Inc. is quite possibly the biotech industry’s best-kept secret. Tackling the mammoth task of aggregating public biomarker data into semantic insights, the company provides pharmaceutical, diagnostic and life sciences companies with key data to help them plan clinical trials, testing and product development initiatives.
So how do you consolidate and organize data from across multiple, non-normalized sources to deliver meaningful insights? We recently caught up with co-founder and CTO Chris Kraybill, who told us more about BiomarkerBase™, precision medicine, and how Amplion is providing the intelligence behind the next generation of diagnostic solutions.
_ Hi Chris, can you tell us a little bit about Amplion and how the company came to existence? _
We were founded in 2013 because of an acute need to understand the technical and market realities of biomarkers. John Audette, our co-founder and former CEO of a mitochondrial assay company called MitoSciences had a problem with prioritizing his product development efforts. Not only was it difficult to analyze the vast information sources that referred to biomarkers, but the creative naming of molecular entities made it difficult to understand the market. Plus, trying to interrogate public sources of information to gain insights always left something missing.
John first teamed up with scientist and biochemistry PhD, Adam Carroll, who is our other co-founder. Their goal was to provide a comprehensive, accurate and up-to-date source of biomarker information. Our mission was to use a combination of data science and hard sciences to automate the discovery phase of product portfolio management.
Since then, our collective passion for precision medicine has developed and emerged because the link between biomarkers, companion diagnostics, and precision therapies has become well accepted and can be supported through the data aggregation and analysis done with our flagship product, BiomarkerBase. We now see our role as leading pharmaceutical and diagnostic companies into the era of precision medicine. By identifying the relationships between biomarkers in diagnostic tests, therapeutics, and the participating companies who develop these, we are able to identify product development opportunities, strategic partnerships, and help our customers understand the competitive realities.
_ Can you give us some examples of how your customers use the software? _
I’d say an interesting use case is with planning clinical trials. A lot of times, pharmaceutical companies will develop a novel compound they want to take to market. So they use biomarkers to stratify patients as part of an inclusion-exclusion strategy to optimally improve the outcome of clinical trials.
Trials that use biomarkers have been demonstrated to have a higher success rate when they try and target certain segments of patients. In a peer-reviewed article that was recently published in Bio where Amplion was one of the co-authors, we demonstrated a 3-fold increase in approvals for clinical trials that incorporate selection biomarkers in trial planning and execution.
Let’s take the example of two patients with kidney cancer. Each patient will have a different gene composition, and will respond to treatment in different ways. This is where applying biomarkers to the trial planning process becomes important. Taking a precision medicine approach allows companies to assess both trial candidates upfront to determine their compatibility and likelihood of responding to the treatment in the same way.
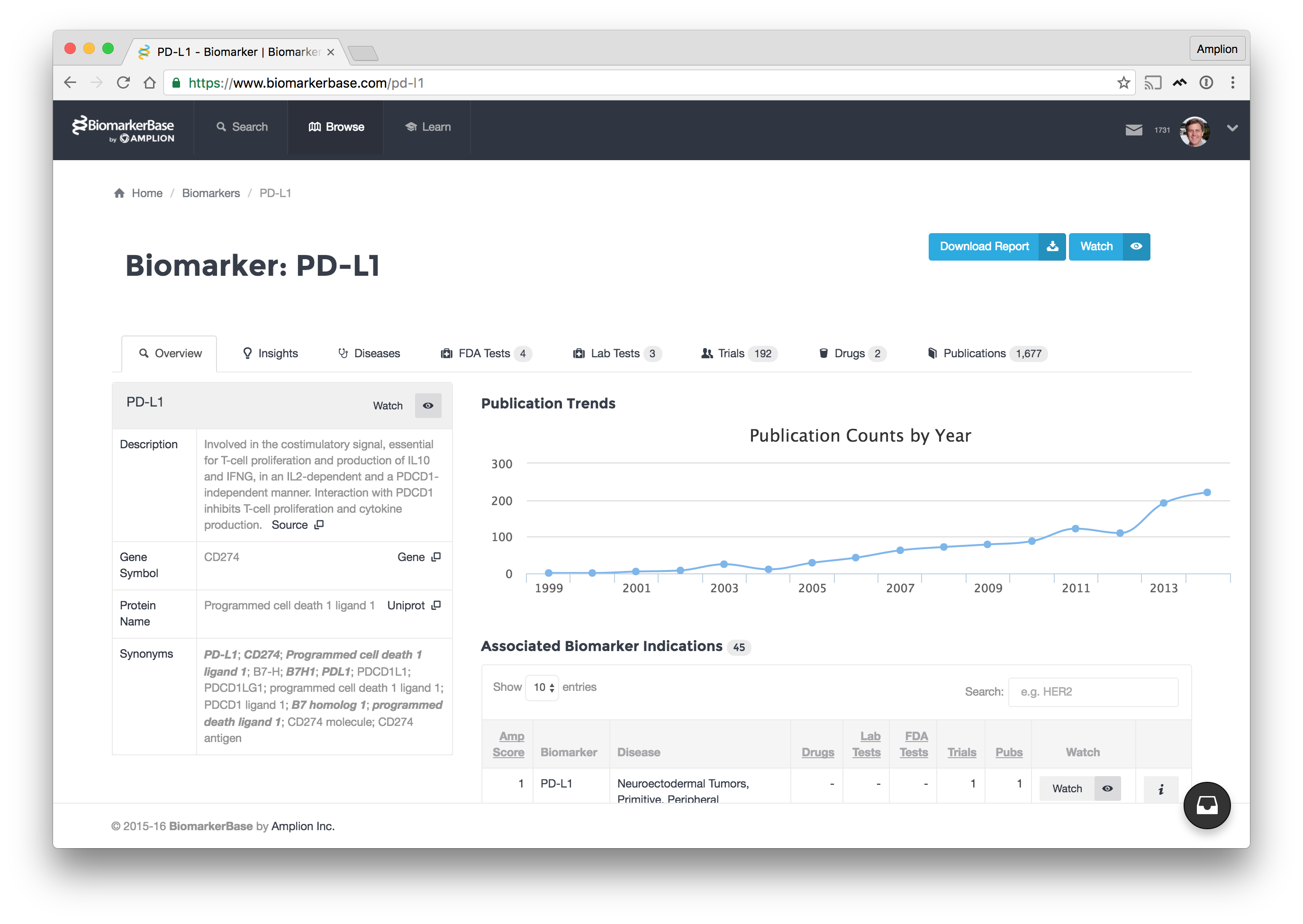
The other use case we see frequently is with diagnostic companies. They want to understand what biomarkers are being used for which type of trials, so they can develop the requisite tests needed to support the companies running those trials, and then ideally to test consumers once a drug has seen approval. They use the data to look for new market opportunities in R&D, while gauging the direction of where the industry’s going.
_ What makes Amplion unique, and why do customers choose you? _
Well the main pain-point we solve for customers is to help them answer the question; what biomarkers should I use? We want to be able to deliver the insights that can inform the decision-making capability of people responsible for developing drug and diagnostic tests.
Of course there are other competitors – large, bioinformatic companies that attempt to provide a similar sort of service. What we try and do is differentiate ourselves in two ways. Our focus is to always take a clinical lens to the data and curate the information in a way that’s meaningful for the end-user. We’ve seen how the competition tends to go out and find the enzymes, find the genes and then push the information into their database. We filter what’s in our dataset, so it can be used clinically with very little manipulation required.
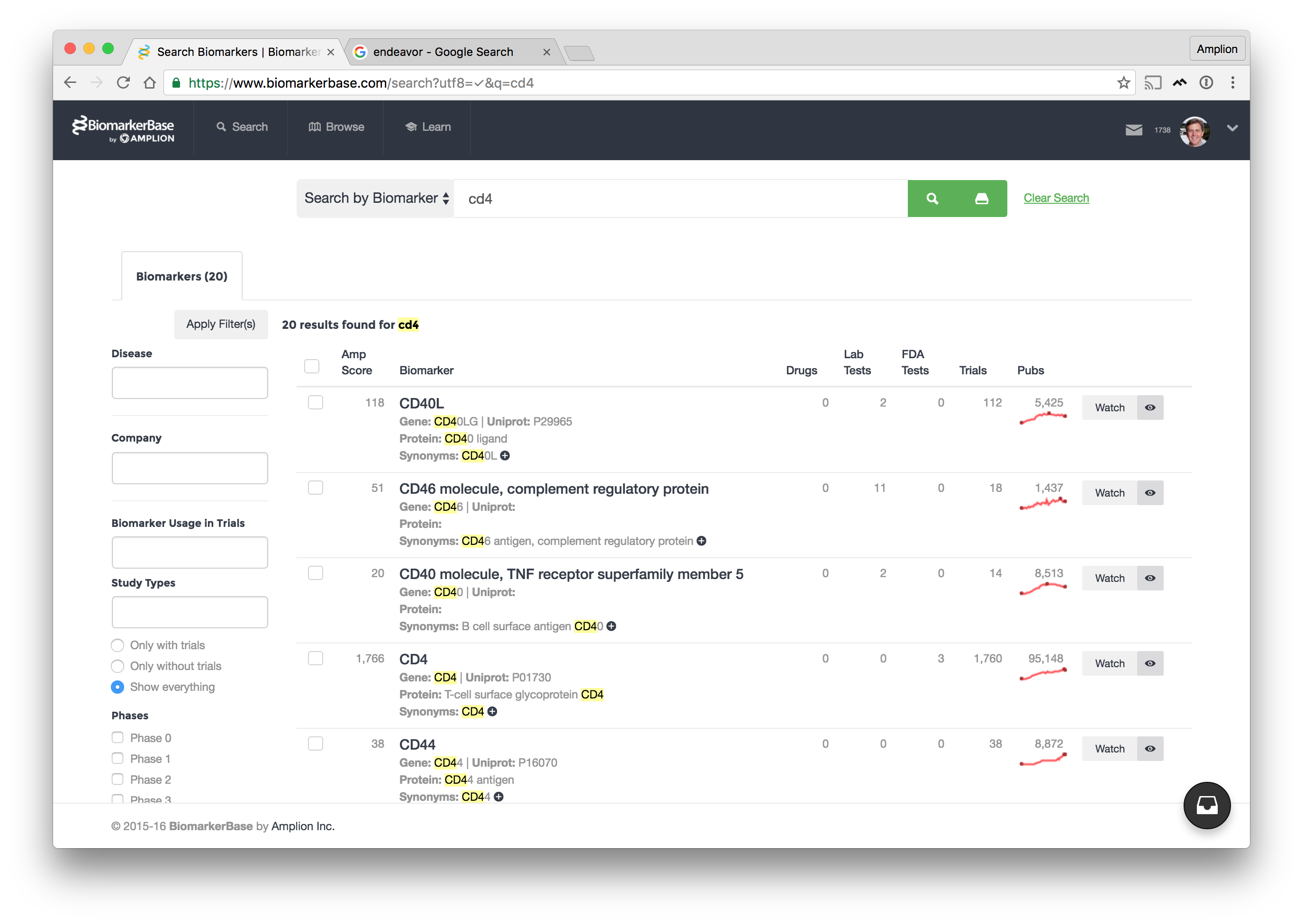
And secondly we take a lot of pride in making the information accessible. We want our users to have easy access to just what they need, when they need it. We've invested our time and energies into creating a straighforward UI and logic-based filters that can be applied with just a few clicks.
_ Can you talk us through what your current infrastructure set-up looks like? _
We have an API and web application, both of which are implemented in Rails. We currently host our infrastructure at Digital Ocean, which Cloud 66 enabled us to do when we transitioned to Rails. All of the customer front-end access and API product access to our biomarker data is configured and deployed via Cloud 66.
We have other components that include Redis for caching and PostgreSQL which we use as our production database. We also rely heavily on Elasticsearch for the faceted search and filtering we provide our customers.
Another really interesting aspect to our infrastructure is how we collect and connect all of the disparate biomarker data we curate. We think of our database as a living cell model. There are a number of natural language processing steps that curate the database before it gets into the hands of our customers. We take these data pipelines to build a new production schema, and after a series of quality steps, we effectively making the new pipeline database the gold standard, which in turn becomes the next production instance. This all happens on AWS.
_ How have you found working with Cloud 66? _
A developer colleague recommended Cloud 66 to us. Like many startups, we originally had this classic Rails monolith and as we started to decompose the application into smaller parts, we found that continuing to run our application at a PaaS service became prohibitively expensive. We didn’t agree with the assumptions it was making for us, and we weren’t also at the stage of company development where it made sense to go bare bones.
Cloud 66 gave us the ability to choose our back end cloud provider, while allowing us to retain similar benefits of working with a PaaS. We like being able to quickly specify through an intuitive web client the number of front-end web apps with the ability to scale, for example or quickly introduce new components to our architecture. I didn’t have to think about manually setting up our infrastructure and didn’t have to worry about how to achieve this. As we’ve grown and our stack has become more sophisticated, we’ve been able to easily add components like Elasticsearch and most recently, some asynchronous jobs infrastructure. The documentation and support is also pretty great.
I should also mention that one of the things we’ve found very attractive about Cloud 66 is the portability you get between cloud providers. While DigitalOcean has been a great hosting provider for us, we’ve started the process of moving everything over to AWS for greater efficiency and productivity. Cloud 66 makes that transition extremely easy.
_ What are some of your favorite Cloud 66 features? _
A lot of our work is very computationally intensive, particularly during data updates. So one of the Cloud 66 features we’ve found really useful is being able to scale up our web or API stacks, run the necessary processes on dedicated hardware and then scale down those hosts once those computationally intensive processes are complete. It’s been very handy for us to use the scaling capability during peak usage periods, as we have a feature where we notify our customers whenever new data becomes available.
Fantastic stuff Chris. One of the things we love about talking to customers is uncovering some of the innovative businesses out there doing some impressive work. Thank you for sharing the Amplion story with us.